
grep vs AWK vs Ruby, and a uniq disappointment
By Bob Mesibov, published 26/03/2017 in CLI
In my data-cleaning work I often make up tallies of selected individual characters from big, UTF-8-encoded data files. What's the best way to do this? As shown below, I've tried grep/sort/uniq, AWK and Ruby, and AWK's the fastest. The trials also revealed an unexpected problem with the uniq program in GNU coreutils.
My testbed was a humongous data table called reference.txt. The file contains 233 million characters, some of which are strange Unicode items.
Alphanumerics
The first trial looked for all the letters and numbers, using the POSIX character class [[:alnum:]]. I've written the commands below to give the same output in a terminal so you can compare the results by eye.
The grep/sort/uniq command applies GNU grep 2.20, followed by sort 8.23 and uniq 8.23 from the GNU coreutils package.
grep -o "[[:alnum:]]" file | sort | uniq -c | pr -t -4
The AWK command uses FS="" to define every character as a separate field, then checks each field in each line to see if it's an alphanumeric character. If it is, it's added to an array which counts character occurrences. The array is then printed out item by item and the results sorted by character with sort. This command uses GNU AWK 4.1.1.
awk 'BEGIN {FS=""} {for (i=1;i<=NF;i++) if ($i ~ /[[:alnum:]]/) {arr[$i]++}} END {for (j in arr) printf("%7s %s\n",arr[j],j)}' file | sort -k2 | pr -t -4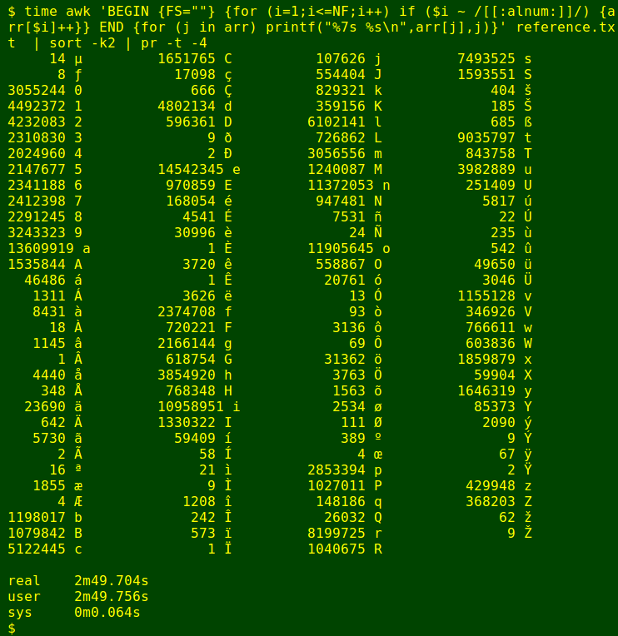
The Ruby command runs a script I modified from one on the Rosetta Code page for "Letter Frequency". My Ruby version is 2.1.5p273 (2014-11-13).
#!/usr/bin/ruby
def letter_frequency(file)
freq = Hash.new(0)
file.each_char.lazy.grep(/[[:alnum:]]/).each_with_object(freq) do |char, freq_map|
freq_map[char] += 1
end
end
letter_frequency(ARGF).sort.each do |letter, frequency|
printf("%7s %s\n","#{frequency}","#{letter}")
end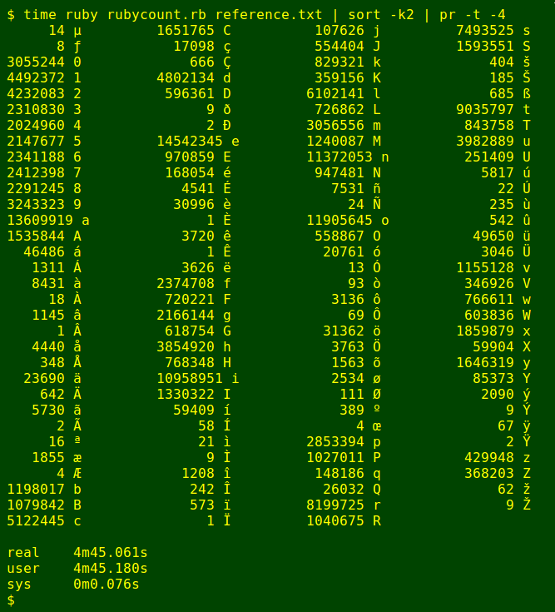
As you can see, all three commands give the same result, but AWK is fastest.
Non-alphanumerics
The second trial inverted the search: I tallied characters matching [^[:alnum:]]. As shown below, AWK was again fastest, but not by much.
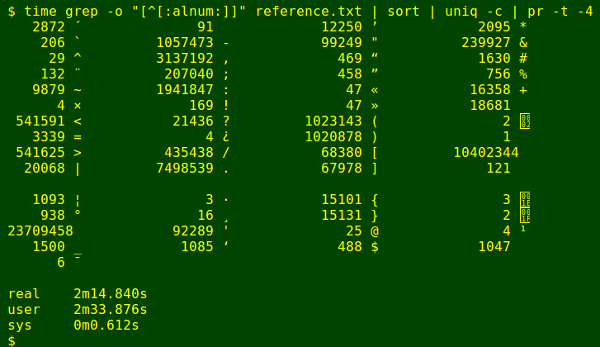
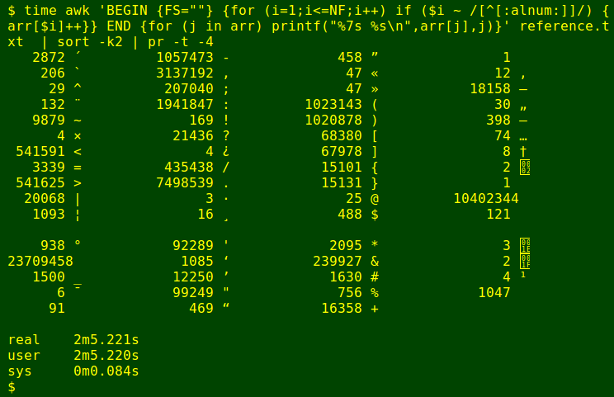
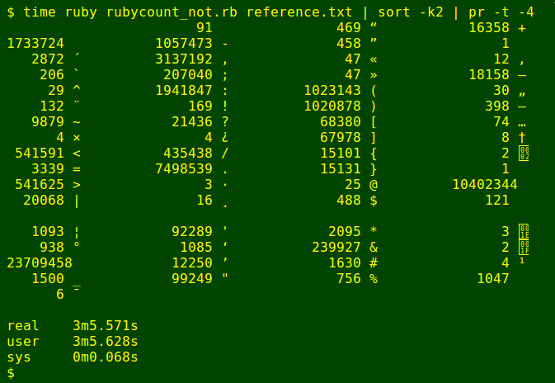
The surprise here is that grep/sort/uniq has stuffed up. If you look at the entries between '16358 +' and '2 [hex 02, start-of-text, STX]', you'll see that AWK and Ruby have found seven different characters totalling 18681 instances, but that all 18681 have been lumped by grep/sort/uniq as a single character. That character is the (one) byte order mark (octal 357 273 277) which begins reference.txt. [I check character identities by running them through od -c. The strange break in the screenshots is caused by the vertical tab character, of which 121 were tallied.]
The following screenshot demonstrates that the lumping is done by uniq:
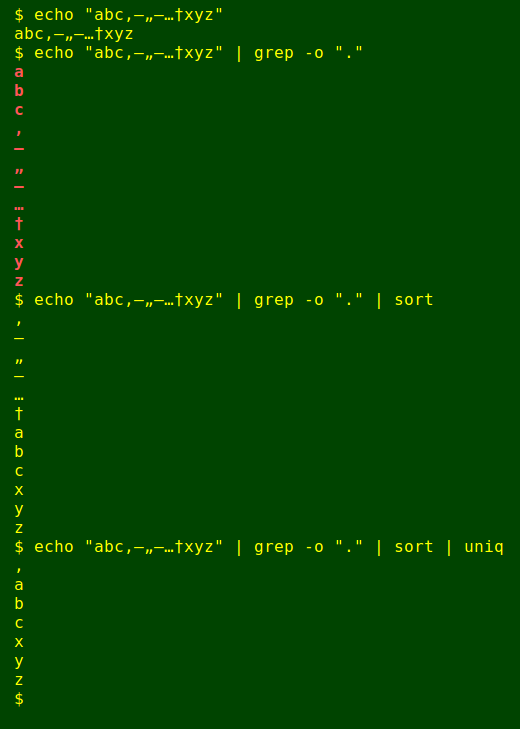
As Trump would tweet, "Sad!"
This bad behaviour by GNU uniq has been complained about before, but the GNU developers don't seem to consider it a bug. In any case, I use the faster and more reliable AWK for character tallying in my work. Note that I can't use a LC_ALL=C workaround. With that locale setting, the non-ASCII Unicode characters aren't recognised.