A simpler track-changes script
By Bob Mesibov, published 13/11/2017 in Tutorials
Back in March 2015 I blogged about a track-changes script that reports the edits made to a tab-separated data table. The script actually generates two reports: a plain text version and a fancy HTML version. A slightly improved version of that script is on my data-cleaning website here.
The script works well for small tables, but the HTML report, especially, is impractical for really BIG tables. This article shows off a track-changes script that simply lists all the edits made, data item by data item.
The script
#!/bin/bash
stamp=$(date +%F_%H:%M)
paste "$1" "$2" > merged
totf=$(head -n1 "$1" | awk -F "\t" '{print NF}')
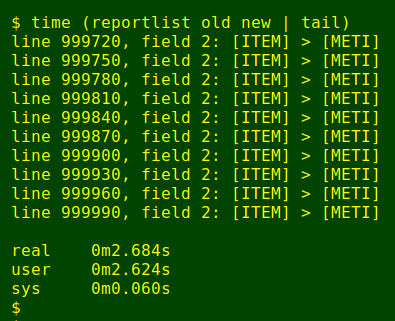
awk -F "\t" -v f="$totf" '{for (i=1;i<=f;i++) if ($i != $(i+f)) print "line "NR", field "i": ["$i"] > ["$(i+f)"]"}' merged | tee "$1"-changes-"$stamp"
rm merged
exit 0The reportlist script above takes two arguments, namely the filenames for the original and edited tables, both of which have tab-separated fields and a single header line. As with the other script, the original table must not have had lines added or deleted, so that lines 1, 2, 3 etc in the edited table correspond to lines 1, 2, 3 etc in the original.
The script pastes the two tables together side-by-side with the default separator, a tab, to make a combined tab-separated table called merged. The number of fields in the original table is taken from its header line using AWK and stored in the variable totf.
A single AWK command follows. In each line of merged, AWK compares data items in corresponding fields, one after the other. For example, if the original and edited tables each have 8 fields, then merged has 16 fields, where field 1 (from the original table) corresponds to field 9 (from the edited table). If the two data items aren't the same, AWK prints the line number, the field number, the original data item and the edited data item. The data items are enclosed in square brackets to make it easier to see if spaces have been deleted, e.g. [item ] edited to [item].
The results are printed to screen and also to a text file called [original filename]-changes-[current date and time].
Example
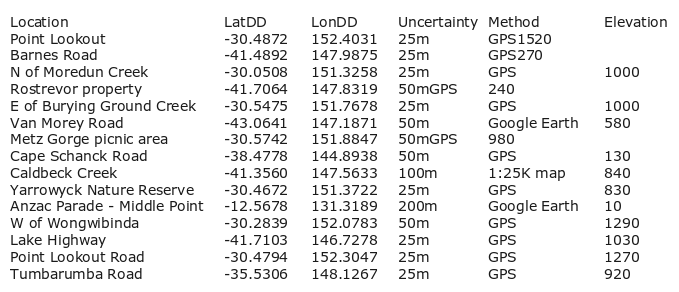
To demonstrate the script I'll use the same demo table as in my earlier Linux Rain post.
demo_old:
demo:
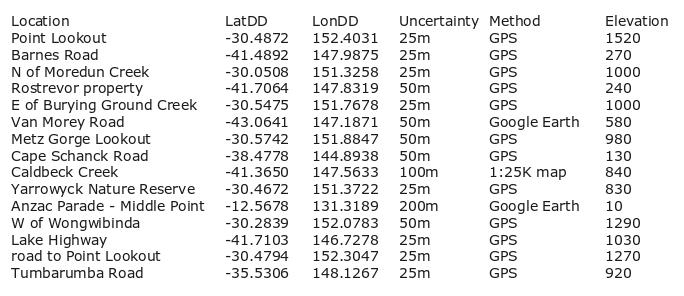
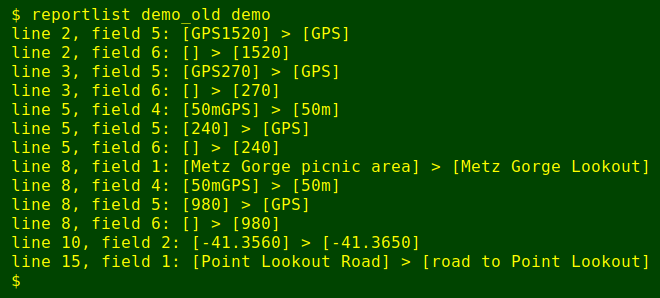
For really big tables, it would be best to pipe the output of reportlist to less.
Performance
You might think that reportlist would take a long time to compare two huge tables. Not so — the grunt work is done by that speed demon AWK. As a trial, I generated a million-line, 5-field, 25 MB table called old. Here's the command for the 10-line version:
printf "%0.sitem\tITEM\titem\tITEM\titem\n" {1..10}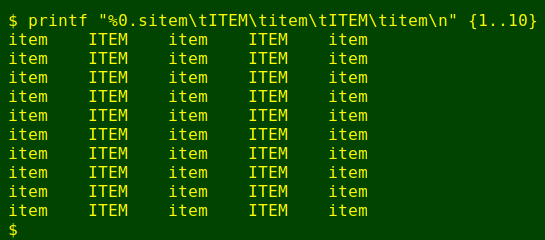
I then edited the second field in every 30th line to generate the file new. Here's an every-3rd-line version:
printf "%0.sitem\tITEM\titem\tITEM\titem\n" {1..10} \
sed '0~3s/ITEM/METI/'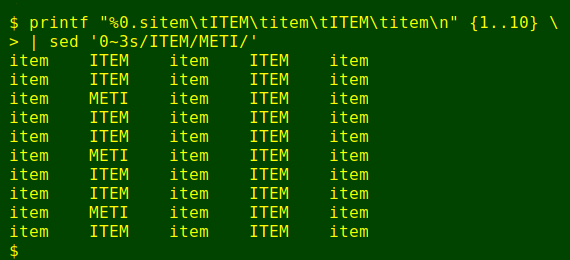
And the time it took for reportlist to do its job and print just the last 10 lines to screen? Less than 3 seconds. The accompanying 33333-line report file is 1.3 MB.