
The header line: how to add, delete and ignore it
By Bob Mesibov, published 21/09/2014 in Tutorials
In a plain-text table, the first or header line usually contains the names of the fields. In this article I've pulled together a variety of ways to add and delete a header, and also how to do things with the rest of the table while leaving the header intact as the first line in the file.
Add a header and create a new table
Adding a header is easy to do without changing the original table. As always with file manipulations, this is A Good Thing. You finish up with the table complete with its new header, and you also have a back-up of the original table.
The table I'll use for demonstration purposes is a modified version of the one I used in this Linux Rain article. The modified file, here called 'table', contains tab-separated fields listing International Test centuries scored by the Sri Lankan batsman Mahela Jayawardene, beginning in 2007. The first field lists the runs, the second the opposing side, and the third the date:
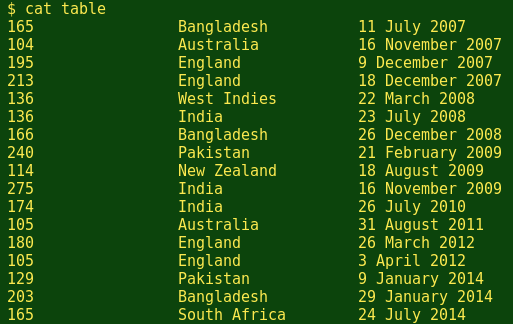
To add the tab-separated field names Runs, Opposition and Date, I can use any of the following commands:
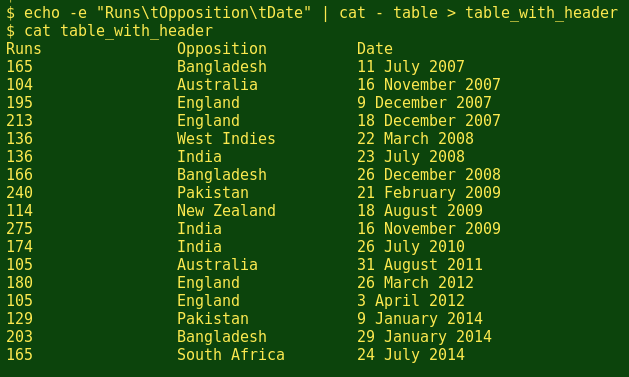
echo -e "Runs\tOpposition\tDate" | cat - table > table_with_header
sed '1i Runs\tOpposition\tDate' table > table_with_header
awk 'BEGIN {print "Runs\tOpposition\tDate"} {print}' table > table_with_header
Add a header by replacing the old table
Are you really sure you want to do this? Let's back up the old table just in case, as table_old:
cp table table_old
There are three simple methods for doing an in-place replacement. One way is to add a header as above, save the result as a temp file, then rename the temp file with the original filename — thus overwriting the original file:
echo -e "Runs\tOpposition\tDate" | cat - table > temp_table; mv temp_table table
A second way is to use the sed command with its in-place option -i:
sed -i '1i Runs\tOpposition\tDate' table
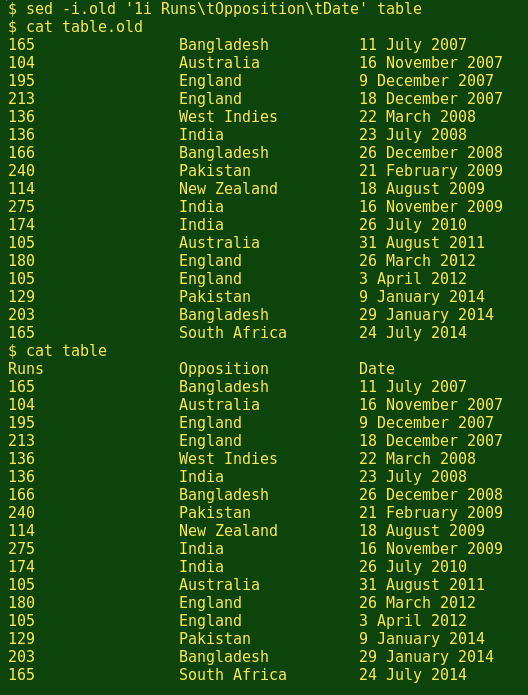
A safer way to use this option is to follow the -i with a suffix, like .old. sed will then copy the original file to table.old before doing the in-place replacement, saving you the trouble of doing a cp table table_old:
sed -i.old '1i Runs\tOpposition\tDate' table
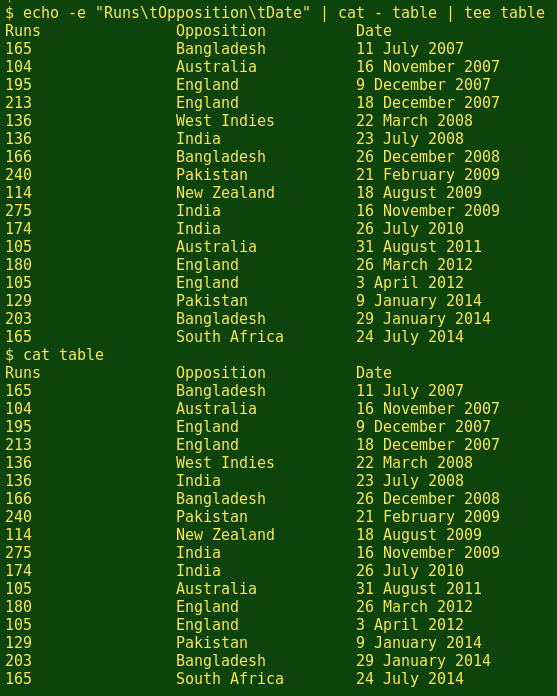
Method 3 uses the tee command to overwrite the original file and send the result to standard output:
echo -e "Runs\tOpposition\tDate" | cat - table | tee table
For the rest of this article, the table file is the one with an added header.
Delete a header and create a new table
tail -n +2 table > table_headless
awk 'NR>1' table > table_headless
sed '1d' table > table_headless
See above for ways to replace the original table instead of creating a new one. With
sed -i.old '1d' table
a backup is created automatically as table.old.
Ignore a header: 1
Suppose you want to sort your table, but you don't want the header to be involved in the sorting. How do you ignore the header?
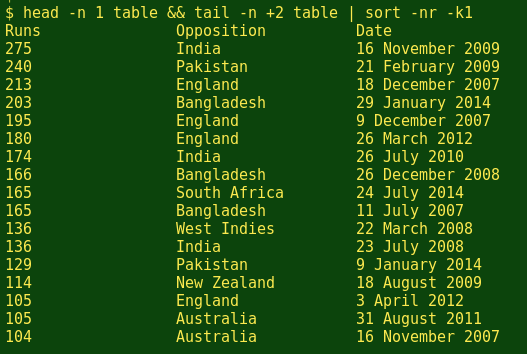
There are two good methods. The first is (print the header line) && (send the rest of the table to sort), where && is a BASH operator operator that only lets the second command go ahead if the first command was successful. Using head to print the header and tail to get the rest of the table, I'll do a sort of the runs totals, in decreasing order:
head -n 1 table && tail -n +2 table | sort -nr -k1
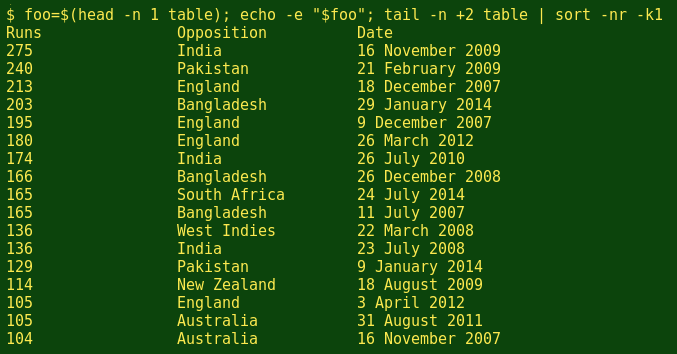
A second method is (store the header line in a variable); (print the variable, including escape characters); (send the rest of the table to sort):
foo=$(head -n 1 table); echo -e "$foo"; tail -n +2 table | sort -nr -k1
Ignore a header: 2
Suppose you want to add a field with a unique number for each record. How can you do this without also numbering the header line?
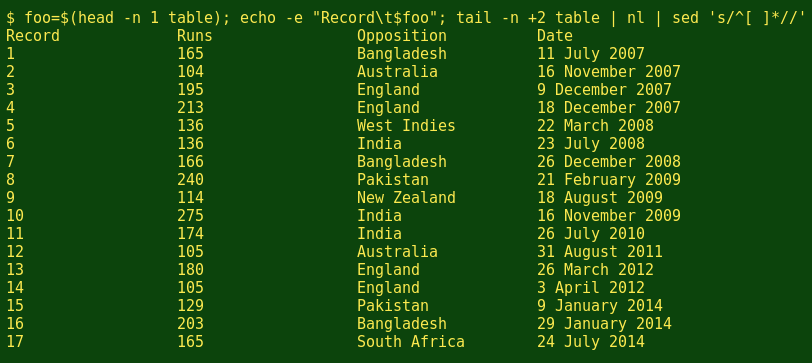
This is a little more complicated, since you also want to add a name for the new field to your header. Once you've done that, you can use one of the 'ignoring' methods and either the nl or cat -n command to number the remaining lines in the table. Unfortunately both nl and cat -n add blank spaces before their numbers. To get rid of those initial whitespaces, I use sed:
foo=$(head -n 1 table); echo -e "Record\t$foo"; tail -n +2 table | nl | sed 's/^[ ]*//'
A much neater way to do this numbering job is with AWK:
awk 'BEGIN {FS=OFS="\t"} {print (NR==1 ? "Record" OFS $0 : NR-1 OFS $0)}' table
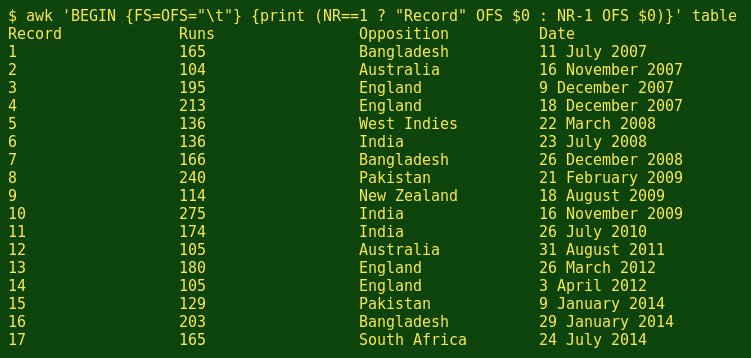
This elegant command uses the AWK 'ternary' operator ? and a colon in an 'if-else' statement. If the first record (NR==1) is being read, then AWK prints the word 'Record' followed by the output field separator (OFS, the tab character \t) followed by the rest of the first record. If the record being read isn't the first one, then AWK prints one less than the record number (NR-1), a tab, and the rest of the line.
Regular readers of The Linux Rain might have noticed that I like AWK — a lot. To my geeky eyes, that last command is gorgeous.