Scripting a 'Find-and-Replace' for big text files
By Bob Mesibov, published 23/04/2014 in Tutorials
EDIT 26/04/2014 I wrote the original fandr script to do single-word replacements in big files. To do multiple-word find-and-replace, the 'needle' variables have to be double-quoted, as in the revised script below. An example of a multiple-word replacement is at the end of this article.
I use two different GUI text editors. Mousepad does my basic editing jobs in a single window, while Gedit gives me tabbed windows, syntax highlighting and (with the Draw Spaces plug-in) a toggle-able view of whitespace and tabs.
Unfortunately, both Mousepad and Gedit struggle with big text files, say 10 mb and up. Both applications seem to load the whole text file into memory before operating on it. Worse, in the case of Gedit 3.4 the 'Find' function looks ahead as I type in the string I'm after. I can hear the CPU fan on my desktop roaring mightily as Gedit checks a 50 mb file for all cases of 'a', then 'an', then 'ant', then 'anti', then 'antic', then 'antici'...
In contrast, finding strings on the command line with grep is zippety-quick, even for huge text files. String replacement with sed is also pretty fast. I recently wrote a simple shell script (below) for finding-and-replacing in some very large text files I was editing. The rest of this article explains how the script works. I'm not very imaginative, so I named the script fandr, for 'f(ind) and r(eplace)'.

Click to enlarge
Line 3. The read command gets my input on what I'm looking for and stores that string as the variable needle1.
Line 4. The read command gets my input on what file to search and stores that path as the variable haystack.
Line 5. Just a spacer to make the terminal output easier to read (see illustrations below).
Line 6. The grep command looks for the needle1 string in haystack and sends all lines where the string is found to the temporary file /tmp/found. The -n option prefixes the lines with their line numbers in haystack.
Lines 7-11. If grep doesn't find the needle1 string in haystack, it exits with exit status 1. If that's the case, the script says 'String not found, exiting', deletes /tmp/found and closes.
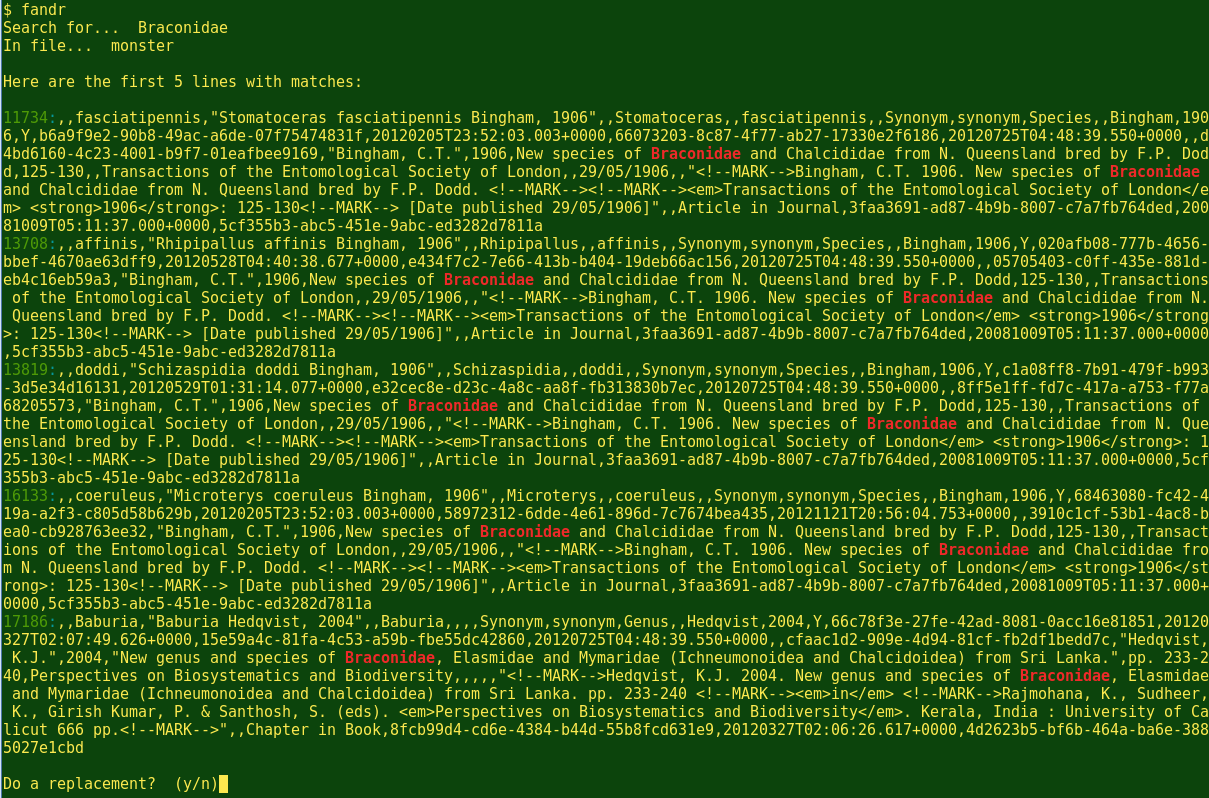
Lines 12-15. If grep has found the needle1 string, the rest of the script executes. First, the first 5 lines containing the needle1 string are displayed. To get those 5 lines, grep again searches haystack and gives line numbers for the matches , but this time the head command returns just the first 5 of those lines (or fewer if there are only 1, 2, 3 or 4 lines with matches). At line 15, the grep option --color=always uses default colouring to display the prefixed line numbers in green and the searched-for string in red (see illustrations below).
Line 17. I may only be looking for the needle1 string without wanting to replace it, in which case I'd like to exit the script at this point. Line 17 asks for a go-ahead on replacing.
Lines 18-22. If my answer to 'Do a replacement?' is n, the script says goodbye, deletes /tmp/found and closes.
Lines 23-38. If my answer to 'Do a replacement?' is y, the rest of the script executes.
Lines 25 and 26. In line 25, I colour the searched-for string red, just so that it will stand out in the line 26 input request. The coloured string is stored as the variable needle1colored. Line 26 asks for a replacement string for needle1 and stores it as the variable needle2.
Line 27. Here the sed command does an in-place substitution (with the option -i) of needle2 for needle1 in the file haystack.
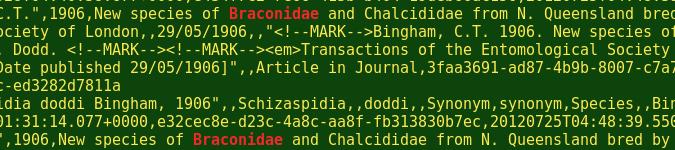
Line 28. The cut commands grabs the line numbers from /tmp/found. These as separated (d:) from the rest of the matching lines with a colon as delimiter (d:; see illustration below) and cut takes the first string before the delimiter with -f1. The resulting list of line numbers is passed to head, which ignores all but the first 5. The list of 5 line numbers is then sent to a temporary file, /tmp/lines.
Line 29. For an explanation of how this interesting command works, see this article. What's happening here is that sed prints only the 5 lines from the edited haystack that are listed in /tmp/lines. The 5 lines with their replacement strings are sent to another temporary file, /tmp/swapped.
Line 30. The paste command here joins the list of 5 line numbers in /tmp/lines with the corresponding list of 5 lines with replacements, /tmp/swapped, using a colon as delimiter (-d:). The resulting paste is sent to yet another temporary file, /tmp/results.
Lines 32-34. The script now displays the 5 lines with replaced strings in /tmp/results, using grep to color the replacements and with the correct line numbers as prefixes.
Line 37. Clean-up time: delete those temporary files!
In the illustrations below you can see the script at work on the demonstration file monster, a 54 mb CSV. (The working directory was the one containing monster.) All up, it took less than 10 seconds to replace the string Braconidae with BRACONIDAE. It takes much longer than that for either Mousepad or Gedit to simply load the 54 mb file, let alone try to do a find-and-replace. With some big files I've worked with, Mousepad and Gedit have simply given up and crashed before completing a string replacement. And I counted slowly to 26 before the spreadsheet program Gnumeric finally opened the monster CSV.
Shell beats GUI for this job.