
Scottish Country Dancing stats
By Bob Mesibov, published 01/02/2017 in Tutorials
My wife has been in the same Scottish Country Dancing group for many years, and back in 2005 she began keeping a record of the dances done at each meeting. She lists a fair bit of information in her "dances done" spreadsheet (screenshot below).
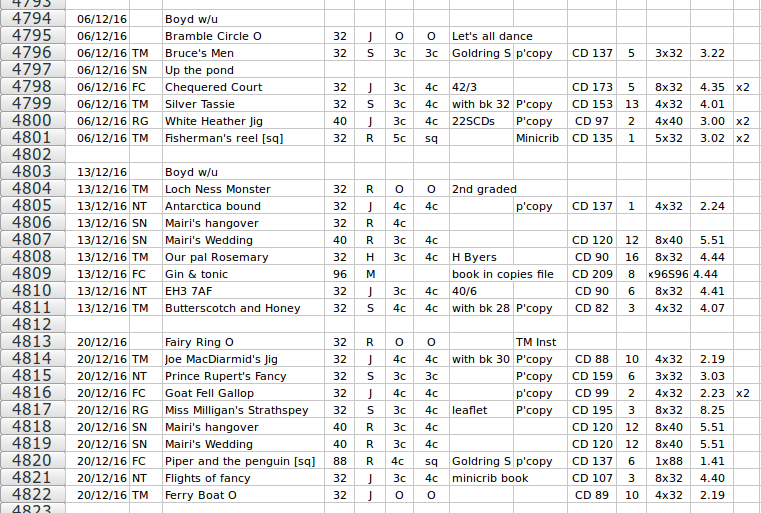
She recently asked me "Would it be possible to get a summary by dance title? For each title I'd like the total number of times we danced it, and also the number of years in which we did that dance."
Well, it could be done with a spreadsheet pivot table and a function or two (after data cleaning, see below), but to me it sounded like a job for the command line. Quick, Robin! To the Bat-shell!
Conversion to text
I copied the first three columns from the "dances done" spreadsheet and pasted them into a text editor as a new file, table0. This automatically tab-separated the columns and rescued the dates from the clutches of the spreadsheet's Date Monster, turning the dates into harmless strings:
Next I cut out the two columns I wanted, namely date and dance title, to make table1:

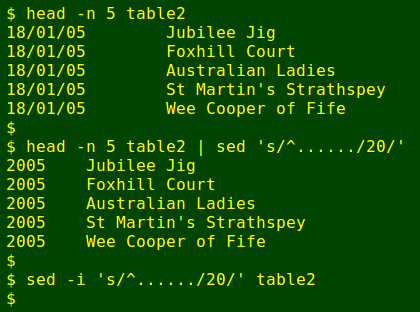
After deleting extraneous lines to make table2 (see this article's data cleaning sections, below) and checking that every date in field 1 had the form dd/mm/yy, I converted all the date strings to their corresponding years with sed:
I then cleaned the dance title field to ensure that all entries were actually dance titles (table2 > table3) and that each title was represented by a single consistent text string (table3 > table4). Over 10+ years of data entry you could expect dance title variants to appear, and they did. The dance "Shiftin' Bobbins", for example, appears in table3 as shown below, where the numbers are the number of occurrences of each variant:
1 Shiftin' bobbins
7 Shifting bobbins
18 Shifting BobbinsAfter many deletions and substitutions (see the data cleaning sections below, if you're interested), table4 was ready for summarising. I did this in two ways. The first used pipelines of simple commands, and the second was nearly pure AWK.
Building the summary with pipelines
echo -e "Dances\tTimes\tYears" > summary
paste <(cut -f2 table4 | sort | uniq -c \
| sed 's/^[ ]*//;s/ /\t/' | awk 'BEGIN {FS=OFS="\t"} {print $2,$1}') \
<(sort table4 | uniq | cut -f2 | sort | uniq -c \
| sed 's/^[ ]*//;s/ /\t/' | cut -f1) >> summary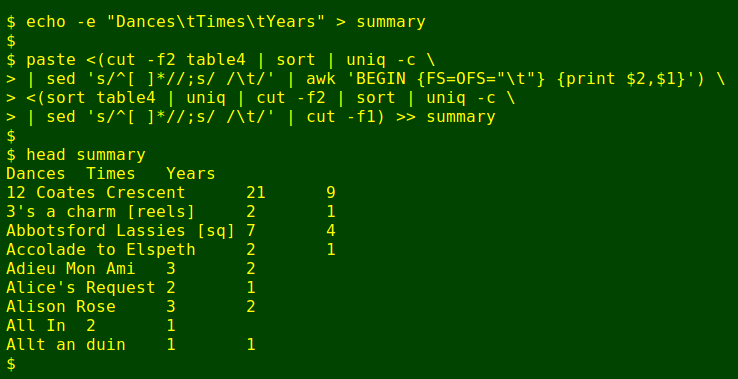
And here's the output summary pasted into a spreadsheet, looking neat and tidy:
The first command echoes a header line to a new text file, summary. The second command pastes together two command results (with the default separator, a tab) and appends them to summary.
The first pasted command cuts out all the dance titles from table4, sorts them and uniquifies and counts the unique results (with uniq's '-c' option). The output of uniq -c is a right-justified column of numbers followed by one space followed by the dance titles. To get that into dance title/tab/number order I use sed and AWK. First sed deletes all the leading spaces in the right-justified numbers column, then it replaces the first space it sees (after the numbers) with a tab. The tab-separated result is sent to AWK, which reverses the order of the tab-separated items.
The second pasted command does almost the same, but the starting list isn't the whole of table4, but a list of unique year/dance title combinations. I get that by passing table4 through sort and uniq first. From the final uniq -c count I only want the number of years, which is cut out with cut -f1. The sorted dance titles are in the same order as in the result of the first pasted command, so the 'years' numbers are in register with the 'times' numbers.
Building the summary with AWK
The pipelines method uses 13 commands (cut 3, sort 3, uniq 3, sed 2, awk 1, paste 1). My second method for getting the summary figures does the work in one AWK and one sort.
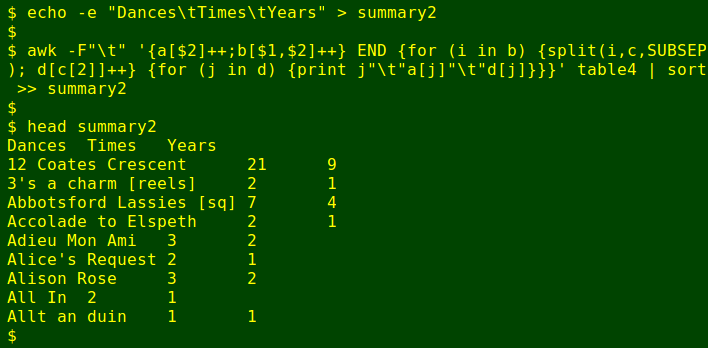
echo -e "Dances\tTimes\tYears" > summary2
awk -F"\t" '{a[$2]++;b[$1,$2]++} END {for (i in b) {split(i,c,SUBSEP); d[c[2]]++} \
{for (j in d) {print j"\t"a[j]"\t"d[j]}}}' table4 | sort >> summary2As AWK goes through table4 line by line, it builds two arrays. Array 'a' keeps track of the number of times each dance title appears in the table. Array 'b' keeps track of the number of times each unique (year+dance title) combination appears in the table. Within array 'b', the year and the dance title are concatenated with a non-printing character in between, referred to in AWK-speak as 'SUBSEP'.
When AWK has finished reading table4 it does the actions in the 'END' portion of the command. The first action is to loop through all the unique, concatenated strings and split them into the parts joined by SUBSEP, called '1' (years) and '2' (dance titles), and put them into a 3rd array, 'c', as elements. The dance-title part ('c[2]') is then counted in a 4th array 'd' by putting an array within an array. If a dance appears in 'n' different years, the value of d["dance"] is 'n':

The final AWK action is another loop. For each of the dance titles in array 'd', AWK prints the dance title (j), the total number of times it was danced (from array 'a', which is indexed to dance title), and the number of years it was danced (from array 'd', which is also indexed to dance title 'at one remove'). The output is sorted because array contents in AWK are unsorted and the AWK way to sort is more complicated than just piping to sort.
Cleaning the data: consistency checks
Some data scientists claim that up to 80% of their work consists of cleaning data! I didn't spend quite that much of my time cleaning my wife's dance data, but it wasn't a quick job. If you're interested in how I cleaned, read on.
Every line in table1 should have a date in the form dd/mm/yy (in field 1). I checked that by counting characters in field 1 — the count should be eight:
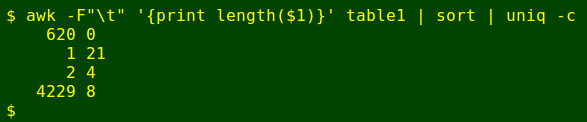
Hmmm, three non-useful lines and 620 blanks. Do all those 4229 8-character first fields have the right format?

Looks good, but do all those 4229 records also have at least some letters in the dance name field?

That's interesting. What are the seven exceptions?
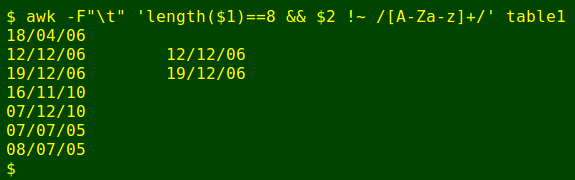
So I extracted the 4222 potentially useful records as table2:

Cleaning the data: deletion
The easiest way to check for dance title consistency was to cut out field 2 and sort and uniqify it, like this:
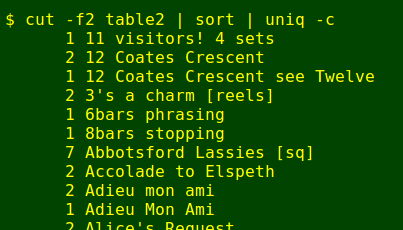
Scanning the list, I noticed dance title entries which weren't dance titles at all, and those lines needed to be deleted. Bulk deletions can be done with a single sed command. The trick is to create a new text file containing the patterns to be deleted. To demonstrate I'll use the file file:
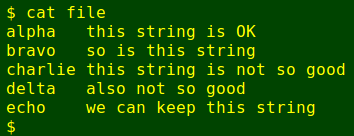
Opening a text editor next to my terminal on the monitor, I copy/paste the lines to be deleted (highlight to copy, middle-click to paste) and save the new text file with the delete-able lines as dels:
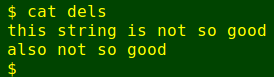
Next, I use sed to turn the list into a set of sed deletion jobs:
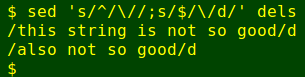
and feed the result to sed with its '-e' option (note the double quotes). sed does each of the deletions in turn:
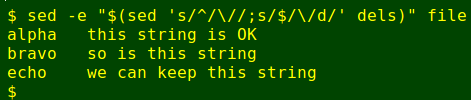
Some characters have to be escaped in dels, like the forward slash in my wife's abbreviation for "warmup", namely "w/u". To avoid sed interpreting that forward slash as the start or finish of a regex, I escaped it with "w\/u". Other literal characters that need to be escaped in a sed regex are $, ., ^, \ and the square brackets used to define character classes, [ and ].
A simpler alternative to sed for bulk deletions is grep. You can use the '-f' option to call the file of patterns to be deleted and the '-v' option to invert the search:
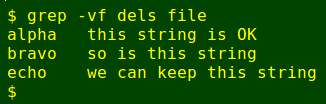
With those literal characters escaped with backslashes in the dels built from the sorted and uniquified list of dance titles, I passed table2 through the following sed command, bulk-deleting many lines to create table3:

Cleaning the data: substitution
Many of the field 2 variants differed only in having a trailing whitespace or two after the dance title. I cleaned these with:

As with bulk deletions, copying/pasting can be done to create a file of substitution jobs, subs, once again escaping any special characters. The subs file can then be fed to sed for bulk replacements:
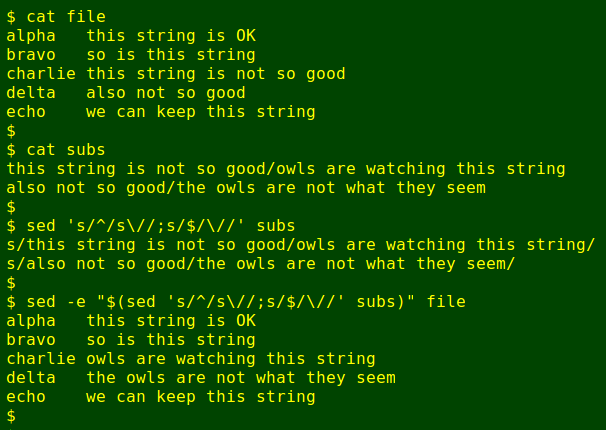
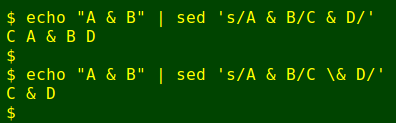
One "gotcha" is that an ampersand character (&) on the right-hand side of a sed substitution regex has a special meaning. It stands for "everything on the left-hand side", so if you want the replacement string to contain a literal ampersand, it has to be escaped:
After checking subs carefully for problems, I ran

to get table4, which had more than 4000 consistently formed dance titles and the years they were danced, ready for summarising.
For data geeks...
If you'd like a broader introduction to command-line data cleaning, check out my website, A Data Cleaner's Cookbook.
[Background image by Hawaiibrian, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=45595127]