
Hunting gremlin characters
By Bob Mesibov, published 21/10/2016 in Tutorials
When cleaning UTF-8 text files I sometimes come across invisible characters that I call 'gremlins'.
These aren't the usual non-printing characters, like whitespace and (horizontal) tab, which are non-printing characters I expect to find in the plain text files I work with. Gremlins are weird things like 'vertical tab', 'device control 2' and 'soft hyphen'. I don't know how they got into the files, but I want to get rid of them.
Hunting
Unless you deliberately hunt for gremlins, you can easily miss them. Here's an example, from this webpage:
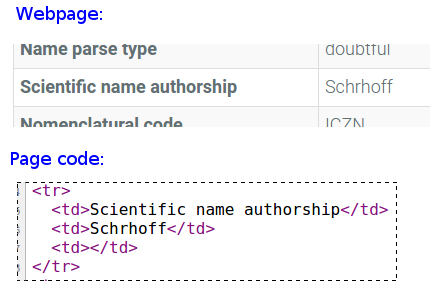
It looks like there's a character missing before the 'r', both on the webpage and in its page code. In fact, there's a gremlin before the 'r', as you can see if you copy the 'Schrhoff' from either page and paste it into a terminal or a text editor:
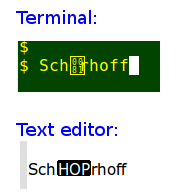
In this case the gremlin is the 'High Octet Preset' character, hex 81, a.k.a. 'HOP'. Since it's a control character, HOP might be detectable with grep and the POSIX control character class, and it is:

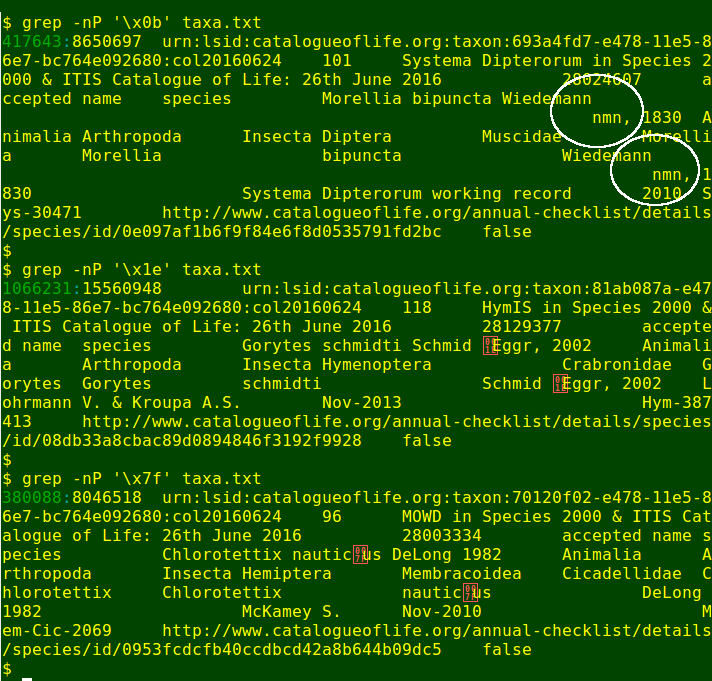
That POSIX class, however, includes the control character (horizontal) tab, which isn't a gremlin, so a search for control characters in text would also find all the tabs. One workaround is to pull out all the control characters with grep -o, then filter away the tabs. I did that recently with a big file called 'taxa.txt' and got this result:

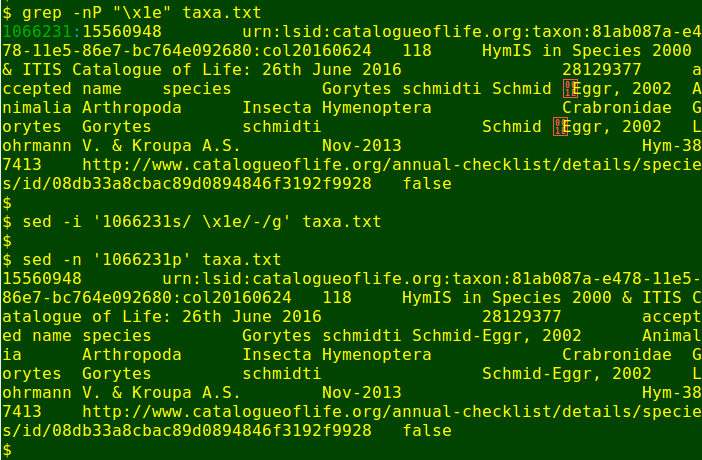
Two each of three gremlins! The first is 'vertical tab' (hex 0b), the second is 'record separator' (hex 1e) and the third is 'delete' (hex 7f). To find the gremlins in the file, I used grep again:
Hunting harder
Two gremlins come from the ISO-8859 world, namely the invisible 'soft hyphen' (hex ad) and 'non-breaking space' (hex a0). Both have been adopted into Unicode and pass without trouble into a UTF-8 file when converting from a ISO-8859-1 or windows-1252 file.
A soft hyphen is placed at a preferred breakpoint in a word, so that programs like Web browsers know where to insert a visible hyphen when splitting the word over two successive lines. In a terminal a soft hyphen appears as a single whitespace, but it's invisible in a text editor.
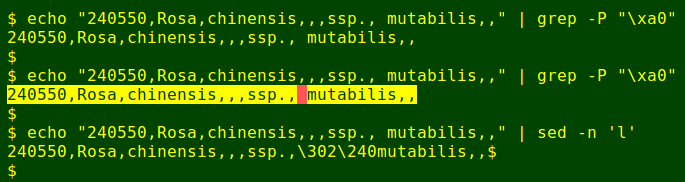
Soft hyphens aren't greppable as control characters or as non-printing characters (with [^[:print:]]). They can be found with a search for their hex value, but they remain invisible until the output is highlighted:

Another visibility trick is to pass the text through sed -n 'l', which reveals soft hyphens as octal 302 255 (hex c2 a0):

A non-breaking space is a character that prevent a line break from happening at its position. Like a soft hyphen, a non-breaking space appears as a single whitespace in a terminal and is invisible in a text editor. Also like soft hyphens, non-breaking spaces can be grepped by their hex code and revealed by highlighting or the sed trick:
Killing gremlins
For some purposes, gremlins can be destroyed globally with tr or sed, using their hex values. I prefer a more targeted approach, as in this example, where a space and a record separator have taken the place of a hyphen in the name 'Schmid-Eggr'. A sed substitution addressed to the particular line in question does the job:
Gremlins from outer space
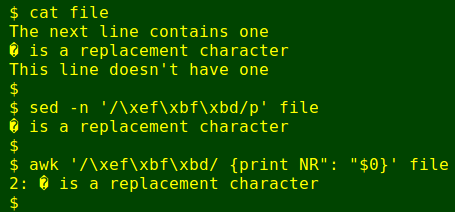
Sometimes a UTF-8 file contains characters that are completely uninterpretable. These will appear on a webpage or in a terminal or text editor as the Unicode replacement character, usually displayed as a diamond with a contrasting question mark.
A replacement character needs to be replaced with whatever character was originally there, and not killed. Discovering the original character might not be easy, but locating replacement characters by their hex value isn't that hard with sed or awk:
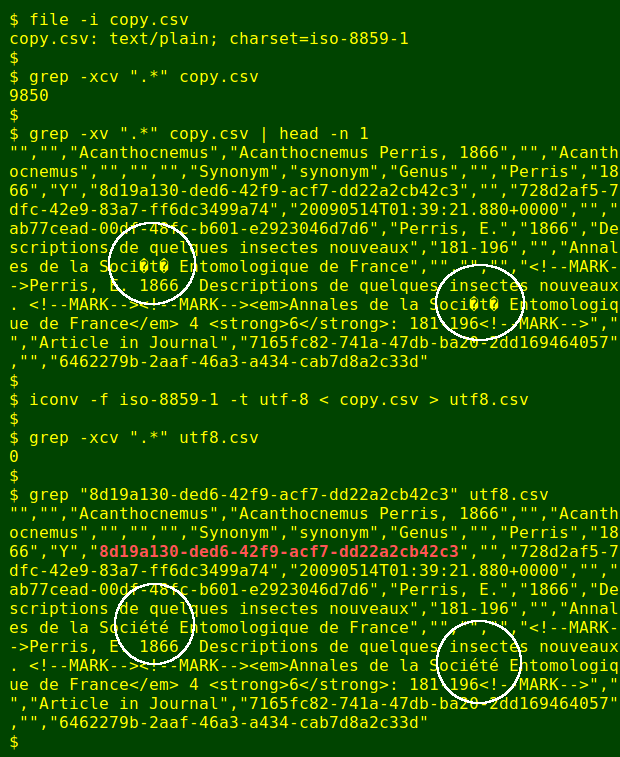
Replacement characters can also turn up when non-UTF-8 files are viewed in a UTF-8 locale. In the example below, 'copy.csv' is ISO-8859-1 encoded. If I grep for non-characters in my UTF-8 locale, 9850 of them are discovered in the ISO-8859-1 file, and as shown these appear in my terminal as replacement characters. When the file is converted to UTF-8 with iconv, the non-characters disappear and get replaced with the Unicode equivalents of the ISO-8859-1 characters:
For more on control characters, see this excellent article.