How to read a file N lines at a time in BASH: 3 methods
By Bob Mesibov, published 29/06/2015 in Tutorials
The file I'll be using for this demonstration is called demo and looks like this:

demo is plain text with 2 tab-separated columns. The first column is sorted alphabetically, but the second column isn't sorted. What I want to find out is how many different letters are in the second column for each letter in the first column. You can see by inspection that the answer is:
Q 4
R 6
S 3
T 5You can also see that to get that answer, I need to read demo 3 lines at a time. The methods described below will do that, and will work for any number of lines, not just 3.
Pasting
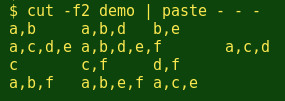
The easiest way to process 3 lines at a time is by using the paste command to turn 3 lines into one. paste can put 3 lines side by side with a tab separator as default. Here's that operation at work on the second column in demo:
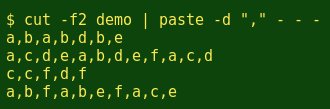
The tab separator can be changed to a comma with the -d option:
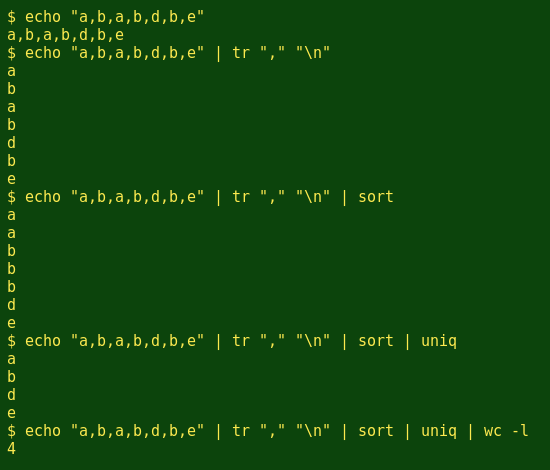
To count unique letters in a line, I'll turn the pasted, all-commas line into a list with tr, sort the list with sort, run the uniq command and count the resulting unique lines with wc. Here's how that works step by step on the first pasted line (the 'Q' letters'):
To work through the pasted lines one by one I'll use a while loop:

My last job is to paste those results together with the unique letters in the first column. Note that the first column was already sorted, so I don't have to sort again before using uniq. Here's the finished 'pasting' command:
paste <(cut -f1 demo | uniq) <(cut -f2 demo | paste -d "," - - - \
| while read line; do echo "$line" | tr "," "\n" | sort | uniq | wc -l; done)
Whiling
Another way to group lines 3 at a time is with a while loop, reading 3 lines and then stopping ('done') before continuing, like this:

The finished 'whiling' command:
paste <(cut -f1 demo | uniq) <(cut -f2 demo | while read line1; \
do read line2; read line3; echo "$line1,$line2,$line3" | tr "," "\n" | sort | uniq | wc -l; done)
xarging
A third but more fiddly grouping method is to use the xargs command and its 'L' (maximum lines) option. It's fiddly because xargs is very particular about whitespace. In this case the commas in the second column of demo have to be converted to whitespace either before or just after xargs deals with the second-column items:
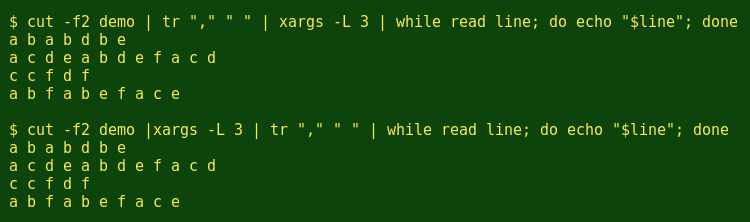
The finished 'xarging' command:
paste <(cut -f1 demo | uniq) <(cut -f2 demo | tr "," " " | xargs -L 3 \
| while read line; do echo "$line" | tr " " "\n" | sort | uniq | wc -l; done)Timing
OK, 3 methods, but which is fastest? To get some idea, I timed another version of the '3 lines at a time' command on a 21 MB file with 1073781 lines, or 357927 sets of 3 lines. The job in this case was just to count the total number of characters in each group of 3 lines, like this:
cat file | paste -d "" - - - | while read line; do echo ${#line}; done > dump1
cat file | while read line1; do read line2; read line3; var=$(echo "$line1$line2$line3"); echo ${#var};done > dump2
cat file | xargs -L 3 | tr -d " " | while read line; do echo ${#line}; done > dump3The result:
paste method 12 seconds
while method 294 seconds
xargs method 258 secondsWell, the relative timings will depend on just what you want to do with each group of 'n' lines, but for jobs like the ones in this demonstration, I think I'll stick with paste.