Building a Desktop Wikipedia Checker
By Bob Mesibov, published 24/11/2014 in Tutorials
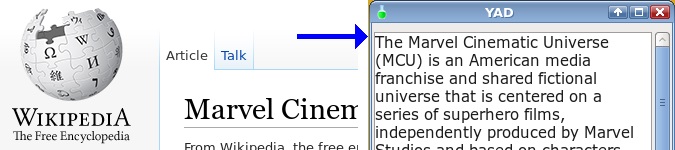
I often look something up in Wikipedia when reading non-browser documents, like PDFs, ODTs and emails. I wanted to have a little desktop window for those look-ups - somewhere I could check Wikipedia without opening a browser and without leaving the document I'm reading.
This article describes how I hacked a simple 'desktop Wikipedia checker' with a shell script. Suggestions for improvements welcome in Comments!
Getting the Wikipedia page
To work with a Wikipedia page outside a browser, I download its page code and save it to a temp file. I use the wget command with the -O (for output) option for the download:
wget -O /tmp/[topic] http://en.wikipedia.org/wiki/[topic]My Wikipedia checker has a dialog box (I like YAD) where I enter the topic. Note that multi-word topics have the words separated by underscores in the Wikipedia page address. For example, the topic 'Marvel Cinematic Universe' has the Wikipedia page http://en.wikipedia.org/wiki/Marvel_Cinematic_Universe. I prefer to use code to substitute any blanks in the entered text with underscores, and variables are the easiest way to do this. I put the entered topic into var1, do the underscoring with a BASH substitution command and store the result as var2, which can then be used by the wget command:
var2=$(var1=$(yad --entry); echo ${var1// /_})
wget -O /tmp/$var2 http://en.wikipedia.org/wiki/$var2Let's try out that code with 'Marvel Cinematic Universe':
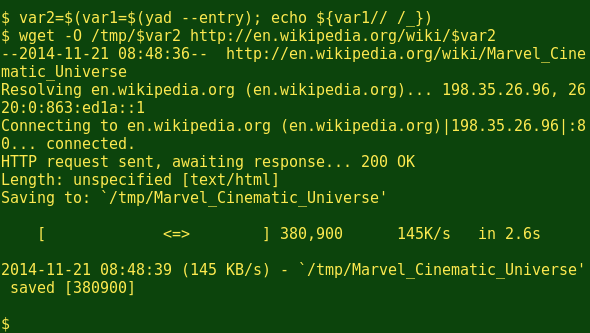
Yep, that works.
Selecting and refining the text
What I want most from a Wikipedia page is what's called the lead. It's the text that introduces a topic and comes before the table of contents. As it says in the Wikipedia style advice, The lead should be able to stand alone as a concise overview... The lead is the first part of the article most people read, and many only read the lead.
The lead is buried in the page code for each Wikipedia page. It isn't identified with a 'div', but it sits just before the page's table of contents, which does have a div, identified as 'toc':

The lead is normally less than 10 lines. I can select out the 'toc' div and the 10 lines before it with the grep command and its -B (for before) option:
grep -B 10 'div id="toc"' /tmp/$var2
The next step is to prune the grepped text down to the lead proper, which is within markup. To do this I use sed with a neat syntax shared in a blog by software engineer Tom Distler:
grep -B 10 'div id="toc"' /tmp/$var2 | sed '/<p.*p>/! {d}'
Finally, I remove all the HTML markup in the lead using another sed command:
grep -B 10 'div id="toc"' /tmp/$var2 | sed '/<p.*p>/! {d};s/<[^>]*>//g'
Let's try it:

Looks OK. If there are fewer than 10 lines in the lead, I'll still get the whole lead text. If there are more than 10, I'll just get the first 10.
Looking better
Time to think about how to present the entry dialog and the results. My display is 1280 x 1024 pixels, and I prefer the dialog and results to appear in the lower right-hand quarter of my screen. I use the code
yad --entry --text="Search Wikipedia for..." --geometry=300x100+900+600 --on-top
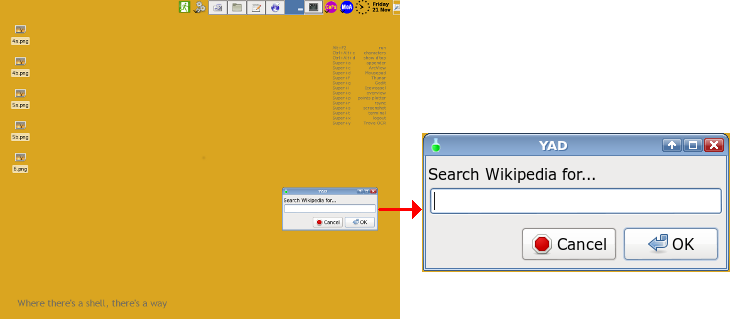
which places the YAD entry dialog where I want it and allows enough width for a Wikipedia topic entry. The --on-top option means the dialog box stays above all other windows until the dialog is closed. This means I can call up the entry box and copy/paste into it a topic from a document in another window.
I use a similar arrangement to display the results of the Wikipedia search. The YAD --wrap option wraps the text within the dialog box, and the scroll bar on the right of the box is a YAD default:
echo $(grep -B 10 'div id="toc"' /tmp/$var2 | sed '/<p.*p>/! {d};s/<[^>]*>//g') \
| yad --text-info --geometry=300x400+900+500 --wrap

But what if?
It's possible Wikipedia doesn't have a page on the topic I'm interested in, in which case the wget command will find a '404' page and the temp file will be created but empty. Before processing the temp file, I test it to see if it has a length greater than zero. If it doesn't, I let myself know with a YAD 'text-info' dialog box:
page=/tmp/$var2 <br><br>if [ -s "$page" ]
then
echo $(grep -B 10 'div id="toc"' /tmp/$var2 | sed '/<p.\*p>/! {d};s/<[^>]\*>//g') \
| yad --text-info --geometry=300x400+900+500 --wrap
else
echo -e "No Wikipedia page for\n$var2" | yad --text-info --geometry=300x100+900+600
fi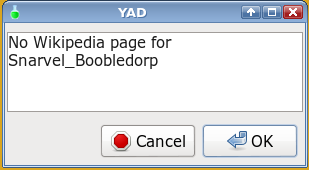
Assembling the script
Putting the pieces together with a couple of simplifications, the shell script looks like this:
#! /bin/bash
var2=$(var1=$(yad --entry --text="Search Wikipedia for..." --geometry=300x100+900+600 --on-top); echo ${var1// /_})
page=/tmp/$var2
wget -O $page http://en.wikipedia.org/wiki/$var2
sleep 4
if [ -s "$page" ]
then
echo $(grep -B 10 'div id="toc"' $page | sed '/<p.*p>/! {d};s/<[^>]*>//g') \
| yad --text-info --geometry=300x400+900+500 --wrap
else
echo -e "No Wikipedia page for\n$var2" | yad --text-info --geometry=300x100+900+600
fi
rm $page
exitI launch the script with the keyboard shortcut super + k. The entry dialog appears over any open windows and is in focus. I enter the topic by typing or copy/paste and press 'Enter' on the keyboard. After a few seconds, either the Wikipedia lead for the topic appears, or my 'not found' message. Both are dismissed with another 'Enter'.
I'm undecided whether to add a YAD 'progress' box to tell me how long I have to wait for a result from wget. Sounds useful, but it would probably be a distraction. The Wikipedia checker looks things up and leaves me to concentrate on the document where those things piqued my curiosity.