
A "Track Changes" script for data cleaning
By Bob Mesibov, published 26/03/2015 in Tutorials
The complicated-looking script at the end of this article is in two parts. The first part detects the changes made when a data table is edited, and reports the changes as a plain-text logfile. It's a straightforward bit of shell scripting based on the diff command. The second part of the script uses AWK and BASH voodoo to transform the logfile into an easy-to-read webpage.
I built the script for a particular kind of data cleaning. I start with a tab-separated data table which has a single header line. This original table gets saved as a backup file. I then go through the working version of the table, correcting any errors in formatting or content, and making sure that data items are in their correct places. This kind of data cleaning doesn't delete any records in the table or insert any new ones. It's just a tidying-up of the data. It's also very fiddly to document or audit, since there can be hundreds of such changes in a big table.
As a simple example, here's a table called demo with 15 lines plus a header, with tab-separated data items in six fields:
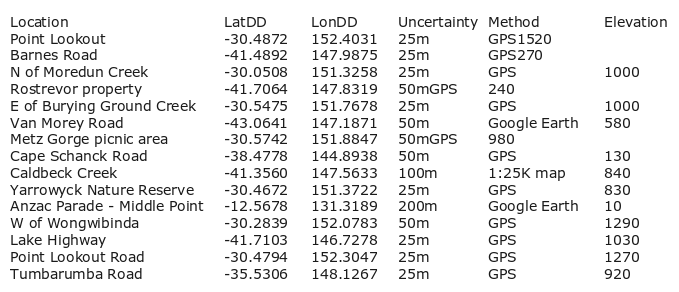
Note that the 'Uncertainty', 'Method' and 'Elevation' items have got mucked up in several of the records. I'd also like to edit a couple of the 'Location' items, and one of the 'LatDD' items contains an error. I first save a backup of demo as demo_old, then clean the data in demo:
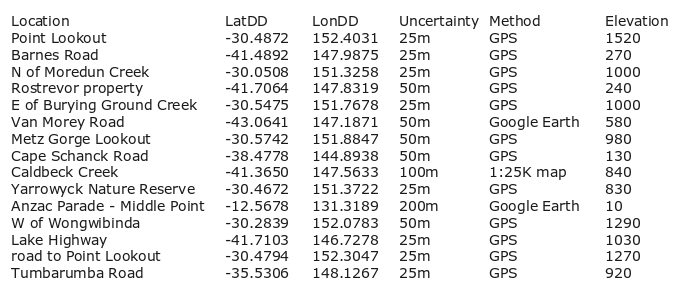
My 'track changes' script is called chgtrkr and is launched by navigating in a terminal to the directory containing demo_old and demo, and entering:
chgtrkr demo_old demochgtrkr generates a logfile in the same directory called demoedits[current date and time].txt and a webpage called demoedits[current date and time].html. The webpage then opens automatically in a browser. Here's the logfile, first as raw text and then with the file opened in (or copy-pasted into) a spreadsheet:
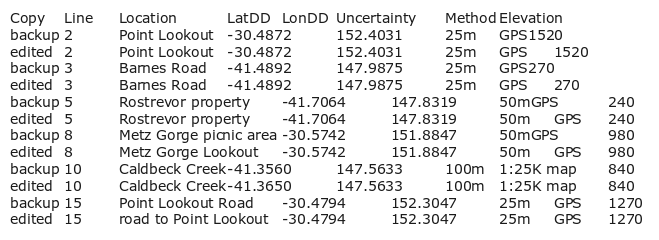
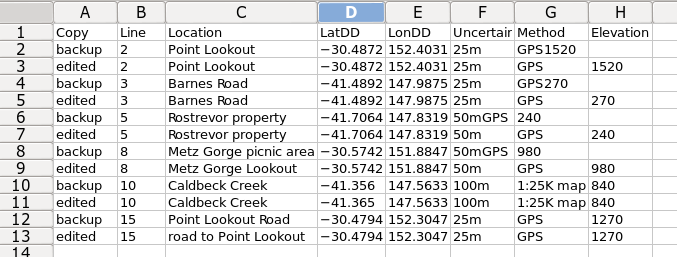
And here's a screenshot of the webpage. Much easier to understand!
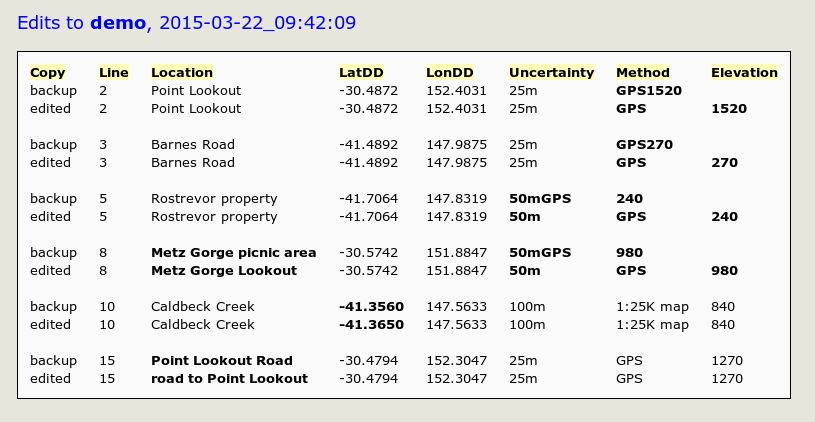
Now to explain the code...
Part 1:diffing and selecting
The script begins by saving the header line of the data table and the current date and time as variables. It then uses the diff command to compare demo_old and demo after the nl command has added line numbers to each. nl adds a line number to the beginning of each line and follows it with a tab. demo_old is argument number 1 for the chgtrkr command and demo is argument number 2:
diff -u <(nl $1) <(nl $2)The particular diff output I use ('unified output') looks like this:
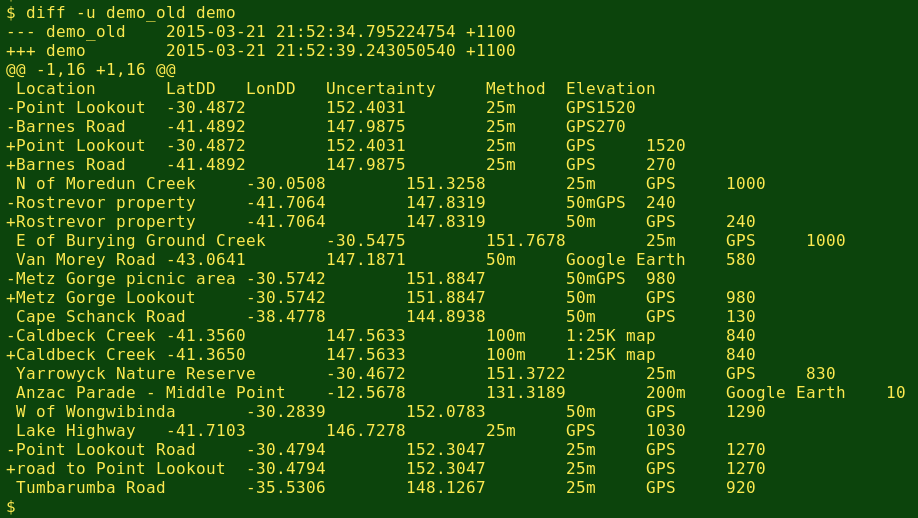
All the lines in the two tables are shown. Unchanged lines (common to the 2 tables) are shown once and not flagged. If a line has changed, the demo_old version is printed with a minus (-) in front and the demo version by a plus (+). There are also three introductory lines in the output. To ignore these first three lines and select just the changed lines (- and + lines) I pipe the diff output to the sed command
sed -n '4,${ /^-\|^+/p}'which in plain English is Starting with line 4, look for lines with an initial - or + and print them [p], but don't print anything else [-n]. I then replace the initial (-) and (+) and their following spaces with 'backup' and 'edited', respectively, followed by a tab. The command is
sed 's/^-[ ]*/backup\t/;s/^+[ ]*/edited\t/'The result is sorted first by line number, then by backup-or-edited, then saved to a temp file called bottom with
sort -nk2 -k1 > bottomNext, a new table header is generated from the old one by adding two new, tab-separated fields at the beginning of the header for 'Copy' (backup or edited) and 'Line' number; this is saved as a variable:
fullheader=$(echo -e "Copy\tLine\t$header")Finally, the enlarged header is added to the top of bottom with the cat command, taking standard input (-) as the first 'file' to be concatenated. The result is saved to a logfile whose name begins with demo and ends with the current date and time I saved as a variable:
echo -e "$fullheader" | cat - bottom > $2_edits_$stamp.txtPart 2: tarting up
That was the easy bit. Now things get a little tricky. As you can see in the webpage screenshot above, I want to show changed data items in bold. But how to distinguish changed items from unchanged ones?
I decided to use AWK for this distinguishing, but AWK works easiest when comparing fields on a single line, so I would first have to put each of the two data items in a before/after pair (backup/edited, demo_old vs demo) on one line, then stack them up again after AWK finished comparing them.
Which is what I do. First I count the total number of fields in the bottom table and save the count as a variable. I get the count by sending the first line of the table (using the head command) to AWK and ask it to print the number of fields in that line. It's two more than the number of fields in demo_old or demo, because I added 'Copy' and 'Line' fields:
fields=$(head -n 1 bottom | awk '{print NF}' )Next, I use a 'for' loop and the cut command to divide bottom into its constituent fields, sending each field to a file named with its field number, like field1, field2, etc:
for ((i=1; i<=$fields; i++)); do cut -f$i bottom > field$i; doneNow for some voodoo. I process all these field files except the 'Copy' and 'Line' ones with paste - -, which puts every two lines on a single line. These rearranged files are then piped one-by-one to AWK. AWK tests to see if the first item in a line (from demo_old) is the same as the second item (from demo). If it isn't the same, both items get printed with bold markup (item) and with a newline between them. This re-stacks the paired data items the way they started in bottom. Here's a simplified example to show how this trick works:
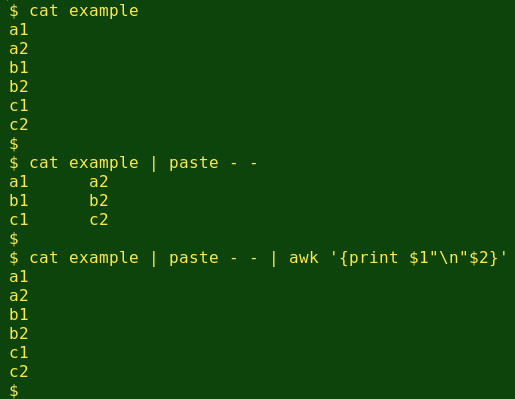
The tested and 'bolded' field files are saved as fieldB3, fieldB4, etc:
for ((j=3; j<=$fields; j++)); do paste - - < field$j \
| awk 'BEGIN {FS=OFS="\t"} {if ($1 != $2) ($1="<b>"$1"</b>") && ($2="<b>"$2"</b>")} \
{print $1"\n"$2}' > fieldB$j; doneNext, bottom is rebuilt by pasting together all its fields:
paste field1 field2 fieldB*I also want the paired before/after lines separated by a space in the final webpage (see screenshot above). I can add a blank line after every second line with sed, but if that line is blank the browser won't read it, so again I do something voodoo-ish. Here sed substitutes the end of every second line in the reconstituted bottom with a newline and the string ' ' (with the '&' escaped), which a browser won't ignore:
sed '0~2 s/$/\n\ /'This also happens to the last pair of lines, so I get an unnecessary ' ' line at the end. I use sed to delete that last line:
sed '$d'In the full command, the reconstituted bottom with its separated pairs of lines is saved as the temp file working1:
paste field1 field2 fieldB* | sed '0~2 s/$/\n\ /' | sed '$d' > working1Now to put a top on working1. I'd like the enlarged header I used in the logfile to be snazzed up with bold text and '<mark>' markup. The latter came in with HTML 5 and its default is to put a yellow background behind an item marked-up with <mark>. It's necessary to do this marking-up separately on each item in the header, because each item is going to be in a separate cell in a table, so I use AWK to methodically do the marking-up field by field. The marked-up header is placed on top of working1 with cat, and the resulting table saved as working2:
echo -e "$fullheader" | awk 'BEGIN {FS=OFS="\t"} {for (k=1; k<=NF; k++) \
$k="<b><mark>"$k"</mark></b>"; print}' | cat - working1 > working2Next step is to get AWK to print out the webpage code that I want. You may not like the CSS styling I've used, and you're welcome to tweak it if you use the script. You can also put a link to an external CSS stylesheet in the <head> section of the page code, rather than spell out the styling in the <head> section as I've done here.
The styling and everything up to and including a <table> tag is done by AWK in a BEGIN statement, which is processed first. I also stick in a styled title for the table, using the 'after' filename (argument 2 to chgtrkr) and the date-time stamp:
awk -v FILE="$2" -v STAMP="$stamp" \
'BEGIN {FS=OFS="\t";print "<html><head><style> \
\n@charset "UTF-8"; \
\nbody, html { padding:30px;background-color:#e6e6dc; } \
\np { font-size:80%;font-family:Verdana,Arial,Helvetica,sans-serif;color:#000000; } \
\ntable { border:1px solid black;padding:10px 0px 10px 0px;background-color:#fafafa; } \
\nmark { background-color: #ffffb8;color: black; } \
\ntd { padding:0px 10px 0px 10px; } \
</style></head><body> \
\n<p style=\"font-size:110%;color:blue;\">Edits to <b>"FILE"</b>, "STAMP"</p><table>"}With all that printed, AWK turns to the main game, which is to process the working2 table line by line (including the header) and mark it up. AWK puts a <tr> first and </tr> last, and marks up each data item, field by field, with <td><p>[item]</p></td> tags:
{print "<tr>"; for (m=1; m<=NF; m++) {print "<td><p>"$m"</p></td>"}; print "</tr>"}With the table processed, the HTML is closed off with an END statement and the finished webpage is saved as a suitably named HTML file:
END {print "</table></body></html>"}' working2 > $2_edits_$stamp.htmlThat HTML file is then opened with my default browser by the xdg-open command:
xdg-open $2_edits_$stamp.htmland the various temp files are deleted
rm bottom field* working*leaving in the directory just the backup copy of the table, the edited table, the logfile of edits and the eye-pleasing webpage version of that logfile.
The script
If you use this script, please remember that it's designed to work with data tables edited without lines being inserted or deleted. If there are insertions or deletions, the neat pairwise ordering of the diff output won't work.
EDIT: The original script only generated the correct HTML if there were 9 or fewer fields in the table. The edited script works with up to 99 fields. The fix is in the command originally ending with "> fieldB$", which produces tested and bolded files numbered fieldB1, fieldB2, etc. To get these pasted together in the right order, the file names need to be fieldB01, fielddB02, etc. This is easily done with the printf command: "> fieldB$(printf "%02d" "$j")".
#!/bin/bash
#Script to track and report changes after cleaning data
#in a tab-separated table with a single header line.
#No insertions or deletions done during cleaning.
header=$(head -n 1 "$1")
stamp=$(date +%F_%T)
#Part 1
diff --suppress-common-lines <(nl "$1") <(nl "$2") | awk '$1 !~ /c/' | sed 's/^>[ ]*/edited\t/;s/^<[ ]*/backup\t/;/---/d' | sort -nk2 -k1 > bottom
fullheader=$(echo -e "Copy\tLine\t$header")
echo -e "$fullheader" | cat - bottom > "$2"_edits_$stamp.txt
#Part 2
fields=$(head -n 1 bottom | awk -F"\t" '{print NF}' )
for ((i=1; i<="$fields"; i++)); do cut -f$i bottom > field$i; done
for ((j=3; j<="$fields"; j++)); do paste - - < field$j \
| awk 'BEGIN {FS=OFS="\t"} {if ($1 != $2) ($1="<b>"$1"</b>") && ($2="<b>"$2"</b>")} \
{print $1"\n"$2}' > fieldB$(printf "%02d" "$j"); done
paste field1 field2 fieldB* | sed '0~2 s/$/\n\ /' | sed '$d' > working1
echo -e "$fullheader" | awk 'BEGIN {FS=OFS="\t"} {for (k=1; k<=NF; k++) \
$k="<b><mark>"$k"</mark></b>"; print}' | cat - working1 > working2
awk -v FILE="$2" -v STAMP="$stamp" \
'BEGIN {FS=OFS="\t";print "<html><head><style> \
\n@charset "UTF-8"; \
\nbody, html { padding:30px;background-color:#e6e6dc; } \
\np { font-size:80%;font-family:Verdana,Arial,Helvetica,sans-serif;color:#000000; } \
\ntable { border:1px solid black;padding:10px 0px 10px 0px;background-color:#fafafa; } \
\nmark { background-color: #ffffb8;color: black; } \
\ntd { padding:0px 10px 0px 10px; } \
</style></head><body> \
\n<p style=\"font-size:110%;color:blue;\">Edits to <b>"FILE"</b>, "STAMP"</p><table>"} \
{print "<tr>"; for (m=1; m<=NF; m++) {print "<td><p>"$m"</p></td>"}; print "</tr>"} \
END {print "</table></body></html>"}' working2 > "$2"_edits_$stamp.html
xdg-open "$2"_edits_$stamp.html
rm bottom field* working*
exit 0