A Pivot Table In AWK
By Bob Mesibov, published 23/05/2014 in Tutorials
GNU AWK is a great tool for working with tables of data, and by using AWK arrays, you can quickly do column sums (and other calculations) based on unique values in another column (see below). Pivot tables in AWK are a bit trickier. In this article I do a slow walk through the code for a simple pivot table.
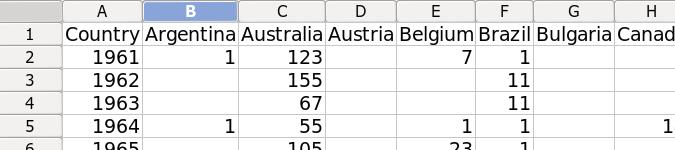
The table I'll use for demonstration purposes (a file called table) comes from a project I recently worked on. It contains information on publications containing scientific names. The tab-separated table has 4 columns and 3393 publications. The columns are: (1) Pub_ID = a unique numerical ID for the publication (1-3393), (2) Pub_country = the country in which the publication appeared (47 countries), (3) Pub_year = the year in which the publication appeared (range 1961-2010), and (4) No_names = the number of scientific names in the publication (range 1-375). The illustration below shows the header line and the first 10 of the 3393 publications. (In this screenshot from a terminal, I've used the 'tabs' program, set here at 15 characters per tab, to make the tab separations clearer.)
Click to enlarge this and following images
To sum up the number of names in each year, I use the following command (broken into separate lines here for clarity, but entered on one line in the terminal screenshot):

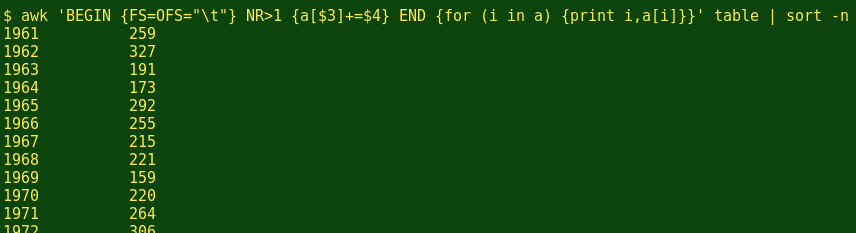
Here the 'BEGIN' statement tells AWK that the input table has the tab character (\t) as a field separator (FS) and that I want the output table to likewise have tabs as field separators (OFS). The 'NR>1' condition tells AWK to ignore the header line, which is record number 1 (NR==1). The action statement 'a[$3]+=$4' creates an array 'a' containing the unique values in the third column, namely the years of publication. Each time AWK sees one of those years as it goes through the table, it adds to the array (+=$4) the corresponding value it finds in the fourth column, namely the number of names in that publication.
The 'END' statement is a 'for' loop, and tells AWK to print each unique year in the array 'a', then the added-up number of names for that year. The resulting 2-column table is piped to 'sort' with the 'sort by number' option (-n), so that the years appear in numerical order.
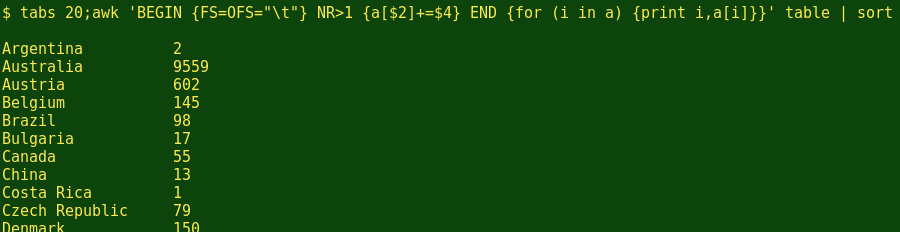
To get a summary by country, I get AWK to build its array from column 2, the countries column, and then do a sort in alphabetical order:

For the next step I'm going to need GNU AWK's 'asorti' function. 'asorti' sounds like it could be a small, tree-climbing mammal from the jungles of Colombia, but it's actually short for 'array sort by index'. Here's the background:
An array in AWK is made up of pairs of strings. The first string is an 'index', and the second is the 'value' associated with that index. In my array 'a[$3]+=$4', the index string comes from column 3 and is a year, like '1961'. The value string is the incremented number of names published in that year. When I told AWK to 'print i,a[i]', I was saying for each index string, print the index string first, then the value string for that index, e.g. '1961' followed by '259'.
The 'asorti' function allows me to sort an array by index. Let's see how this works, using the sum-of-names-by-years example:

In 'END' section of this command, 'asorti' counts the number of entries in the array as 'n'. AWK then works methodically from 1 to n and prints the index strings and the sorted value strings:
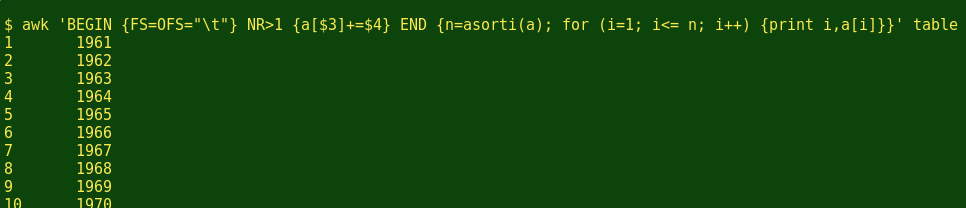
Whoops! What happened? Sure, 'asorti' sorted the index strings in numerical order, but now they appear as the value strings. The original value strings in 'a', namely the sums of names for each year, have disappeared, and there are new index strings, namely the numbers 1,2,3...n.
That's just the way 'asorti' works. To get the value strings as well, I need to get 'asorti' to make a copy 'b' of the array 'a', by writing 'asorti(a,b)'. After sorting, the index strings in 'b' are '1,2,3...n' and the value strings in 'b' are the index strings from the original array. The value strings from the original array 'a' can be recovered with the odd-looking expression 'a[b[i]]'. This can be understood as the value strings from 'a' as indexed, where the index strings for 'a' are the value strings from 'b'.
Let's try it:

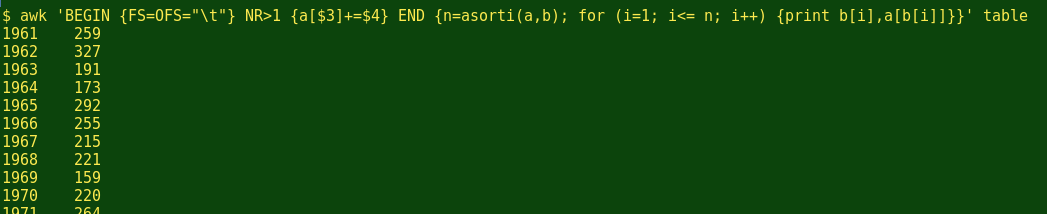
Nice. A little complicated, maybe, but as you can see, I no longer have to do a separate sort of the AWK output table to get the years in numerical order.
The same trick allows me to get sums of names by country in alphabetical order with AWK, without sorting afterwards:
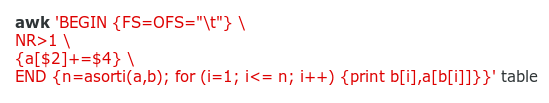
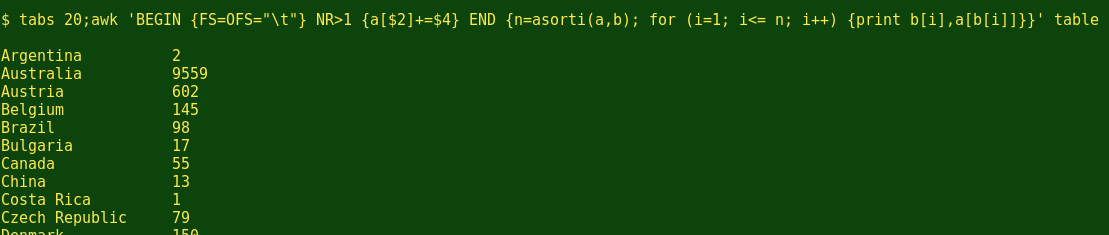
I can now start slowly building my pivot table, which will be years-by-countries. The first row will have "Country" followed by countries in alphabetical order, tab-separated. To build that row:


Looks good; in the screenshot above, the terminal program has wrapped the tabbed items in the output line to fit the screen. Here the array 'countries[$2]++' simply listed all 47 countries, with the country name as index string to be sorted by 'asorti'. Note the use of the 'printf' command without a newline character (\n), to keep the output all on one line.
OK, each succeeding line in the pivot table will begin with a year, then have tab-separated entries, each of which will be the sum of names for that particular year and that particular country. How to get that sum?
With a trick. I'll concatenate the year and country fields in an array, so that the index string will be (for example) '1961Argentina', then increment the value string with the number of names corresponding to that unique index string: 'total[$3$2]+=$4'. Let's see if that trick works, using the code shown above for 'asorti':

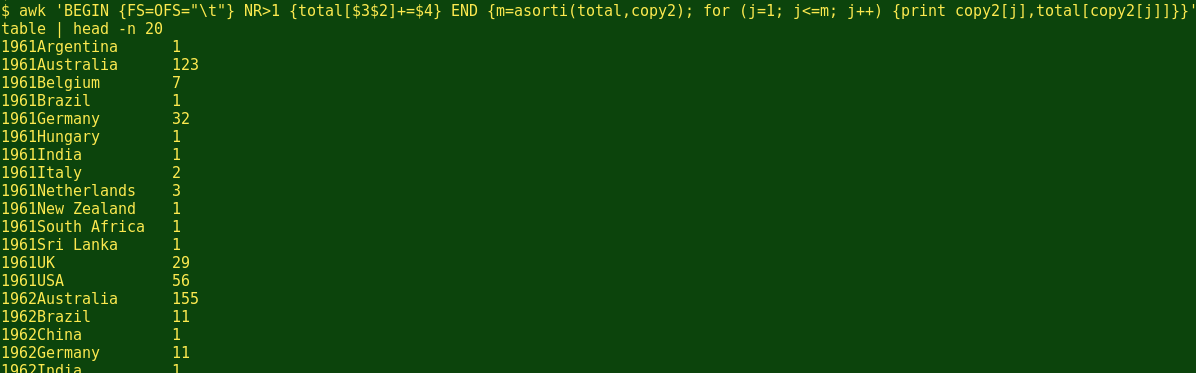
Yes, that works just fine. AWK has summed up the number of names for each year-country combination, and listed the combinations in numerical order.
Now for the last step in building my pivot table, which is to combine the last few steps into a single command. The 'print ""' command is inserted to break between lines in the output:

The output is the tab-separated text file 'pivot', which is a spectacular mess on a terminal screen. If I copy 'pivot' and paste it into a spreadsheet, I get a tidy, 47-country by 50-year table, where each cell entry is the sum of names for the year and country combination. Here's a screenshot of the top left corner of that table in a Gnumeric spreadsheet:
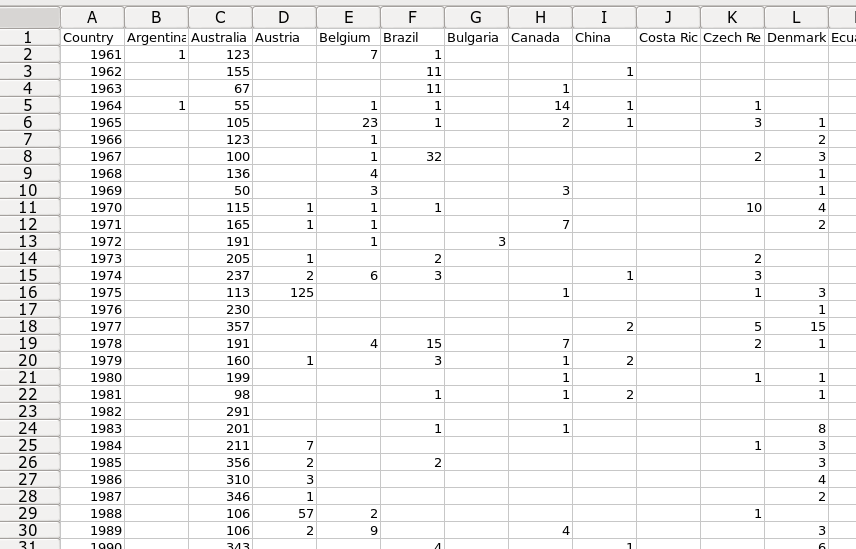
Pivot tables in AWK aren't for the faint-hearted, but they're certainly possible, and if you code a script to build them you'll find that AWK does pivots very fast.